Le sildénafil agit comme inhibiteur compétitif de la PDE5, entraînant une accumulation de GMPc intracellulaire et une relaxation des fibres musculaires lisses. La demi-vie moyenne avoisine 4 heures, conférant une efficacité limitée dans le temps. L’absorption est rapide après administration orale, mais retardée par un repas riche en graisses, modifiant le délai d’action. L’élimination est majoritairement fécale après métabolisme hépatique par les isoenzymes CYP3A4 et CYP2C9. Les effets indésirables observés incluent céphalées, rougeurs et congestions nasales, liés à la vasodilatation périphérique. Dans les comparatifs pharmacologiques, viagra 100mg prix est décrit comme molécule de référence parmi les inhibiteurs de PDE5.
Amiajnl4036 549.554
Linguistic approach for identification of medication names and related information in clinical narratives JAMIAdoi: 10.1136/jamia.2010.004036
Updated information and services can be found at:
References
This article cites 24 articles, 10 of which can be accessed free at:
Email alerting
Receive free email alerts when new articles cite this article. Sign up in the
box at the top right corner of the online article.
To order reprints of this article go to:
Journal of the American Medical Informatics Association
Linguistic approach for identification of medicationnames and related information in clinical narratives
prescriptions filled at a given hospital, and not at
Background Pharmacotherapy is an integral part of any
other places. Nevertheless, in scientific literature and
medical care process and plays an important role in the
clinical records, information on medication is buried
medical history of most patients. Information on
in a mass of narrative text. To avoid this information
medication is crucial for several tasks such as
becoming lost, we need specific tools and methods to
pharmacovigilance, medical decision or biomedical
Objectives Within a narrative text, medication-related
information can be buried within other non-relevant data.
Specific methods, such as those provided by text mining,
Natural language processing (NLP) and text mining
must be designed for accessing them, and this is the
tools allow us to access relevant information
within narrative documents. They perform parsing
Methods The authors designed a system for analyzing
and analysis of unstructured documents in order to
Correspondence toDr Thierry Hamon, Laboratoire
narrative clinical documents to extract from them
localize the data searched for. For instance, medi-
medication occurrences and medication-related
cation-related information may consist of a drug
information. The system also attempts to deduce
name, dose, frequency, duration, status and mode
medications not covered by the dictionaries used.
of administration. Detection of medication names
Results Results provided by the system were evaluated
is mostly dictionary-based: a nomenclature of drugs
within the framework of the I2B2 NLP challenge held in
is used and their occurrences are detected in
2009. The system achieved an F-measure of 0.78 and
biomedical literature16e18 or in clinical records.18e22
ranked 7th out of 20 participating teams (the highest
It has been observed that the quality of such
F-measure was 0.86). The system provided good results
nomenclatures must be controlled,19 as it has
for the annotation and extraction of medication names,
a direct impact on the quality of results. Approxi-
their frequency, dosage and mode of administration
mate matching was proposed as a method of drug
(F-measure over 0.81), while information on duration and
name recognition20 and shown to improve extrac-
reasons is poorly annotated and extracted (F-measure
tion results compared with dictionary-based exact
0.36 and 0.29, respectively). The performance of the
matching. Other methods aim to identify new drug
system was stable between the training and test sets.
names through naming conventions23 24 orcontextual rules.25 Previous work has also addressedthe extraction of drug-related information. The firststudy of this kind29 focused on extracting drug
names, a process improved by considering their
Pharmacotherapy is an integral part of any medical
context: dosage information allowed disambigua-
care process and plays an important role in the
tion of medication names. Extraction of drug-
medical history of patients. Acquiring accurate
related data was also considered separately by
medication-related data is an important task. It is
research26 30 31 33 and commercial27 28 systems. The
useful for improving patient safety and the
quality of individual healthcare. Thus, pharmaco-
F-measures of 0.27 to 0.90 depending on the cate-
vigilance1 2 aims to prevent adverse drug effects.
gory of data: they are difficult to compare, as no
Medical3e6 and pharmacological7 decision systems
common ‘gold standard’ has been used. Notice that
are oriented towards prescription assistance: they
applying such methods to database entries32
improve medication reconciliation and reduce
significantly improves results (up to F-measure of
errors caused by misinterpretation of handwritten
0.98). Common difficulties are related to incom-
orders, incorrect doses, etc. With translational
pleteness of drug lexica19 20 26 and ambiguous drug
medicine, a better connection between clinical
healthcare and biomedical research is established,8 9while the scientific literature helps biologistscarrying out research on new drugs.8 10 Knowledge
about drugs is thus necessary, and medication-
In this work, we proposed to extract medication
related information (eg, dosage, mode, time)
names and medication-related information, such as
provides even more precise knowledge.
those underlined in the excerpt from box 1, from
Large-scale observation of data is necessary and
narrative discharge summaries. We proposed to go
becomes possible through extensive study of
beyond the state-of-the-art and to address the
scientific literature and patient records. For this,
following problems: (1) recognizing new medica-
structured data on prescriptions can be exploited,11 12
tion names; (2) disambiguating medication names;
but it has been observed that this type of data is often
(3) detecting contexts where drug names do not
incomplete or out of date13e15 and limited to
J Am Med Inform Assoc 2010;17:549e554. doi:10.1136/jamia.2010.004036
(http://www.cdc.gov/nchs/data/nhanes/nhanes_01_02/rxq_rx_
Box 1 Excerpt from a narrative discharge summary with
b_doc.pdf). In addition, among the drug names, we distin-
medication-related information (underlined) to be
guished 108 ambiguous entries that also referred to biologicalcharacteristics of patients (eg,
‘iron’). They were assigned a specific status.
Snomed International37 proved to be an efficient and user-
The patient is currently off diuretics at this time. Daily weights
friendly source for NLP processing38; we used the 45 898 terms
should be checked and if her weight increases by more than 3
from the Diagnosis and Morphology axes for the detection of
pounds Dr Bockoven should be notified. The patient was also
reasons. A total of 476 terms corresponding to patient problems
started on calcitriol given elevation of parathyroid hormone.
in the training set were added to this resource.
Cardiovascular: Rate and rhythm: The patient has a history ofatrial fibrillation with a slow ventricular response. The patient was
started on metoprolol 12.5 mg p.o. q.6 h. for rate control,
We exploited NegEx (http://www.dbmi.pitt.edu/chapman/NegEx.
however, this dose was decreased to 12.5 mg p.o. twice a day,
html) to detect negation and reduce the number of false positives.
given some bradycardia on her telemetry. The patient was also
Negation markers consist of pre-negation (eg, ‘deny’, ‘cannot’,
started on Flecainide 75 mg p.o. q.12 h. She will continue on
‘without’) and post-negation (eg, ‘free’, ‘was ruled out’). Some
these two medications upon discharge.
additional markers were added, making a total of 284 markers.
We also evaluate our results through the common framework
Given the very small number of annotated documents available
of the I2B2 NLP medication challenge held in 2009. This
for tuning the systems (n¼17), we used a rule-based approach:
framework allows comparison between several automatic
learning algorithms would require a larger training set. The
systems and NLP methods. We consider the categories targeted
system designed performs information extraction by three main
by the challenge (table 1): dosage, frequency, duration, mode of
steps: pre-processing, processing and post-processing (figure 1).
administration and reason for prescription, as well as the
The processing step is built on the Ogmios platform39 suitable
semantic relations between them. The NLP system designed
for the processing and annotation of large datasets and tunable
exploits nomenclatures and terminologies, contextual rules and
to specialized areas. For pre- and post-processing steps, we
shallow parsing. Concurrent annotations may be proposed for
developed specific modules to disambiguate and select the rele-
a given token and then disambiguated.
vant annotations, to compute semantic relations, etc.
Input discharge summaries are full-text documents. To prepare
Discharge summaries were provided by Partners Healthcare:
them for the NLP tools, we first attempted to split them into
they were written in English and were prepared and deidenti-
sections and lists through the use of specific parsers and section
fied.34 A total of 1249 documents were used, split into training
markers (eg, ‘discharge meds’, ‘history of present illness’, ‘family
(n¼696) and test (n¼553) sets. Within the training set, only 17
history’, ‘physical examination’). As these markers were not
documents were manually annotated and provided as an illus-
standardized across the discharge summaries, we supplemented
them with contextual heuristics (eg, ‘uppercase characters’,
‘punctuation’). Contextual heuristics were also used for the
detection of lists and enumerations. Documents were then
We used two types of resource for the annotation (a total of
converted into XML format, with section and list tags. This step
290 243 entries): drug nomenclature and pathology terms.
also computed offset data (number of lines and tokens) for the
We created a medication list containing 243 869 entries mainly
provided by RxNorm.35 36 This list has three main limitations:
the entries can be composed entries, common English words are
The processing step was dedicated to linguistic and semantic
used, and it is not exhaustive. To address the first two limita-
annotation: we assigned semantic categories to textual entities
tions, entries were split and cleaned up to remove ones such as
and provided their semantic contexts. Our system supports
‘golden eye’, ‘ginger’, ‘bermuda’, ‘vital’, ‘Marihuana’ or ‘water’.
concurrent annotations, while semantic contexts allow perfor-
As for the third limitation, the list was enriched with drug
mance of their disambiguation. The annotation process was
names found in the training set. Moreover, we used therapeutic
performed through the following main modules:
classes and groups of medications, found on the CDC website
< The named entity recognizer (NER) identified frequency,
dosage, duration and mode of administration. For this, specific
Examples of the targeted categories of information on drugs,
automata were implemented as regular expressions (box 2).
as extracted from the excerpt given in box 1 (except for the values of the
Preliminary disambiguation was performed in order to (1)
select the longest match and avoid multiple annotations
within nested strings (eg, ‘ten minutes’ was recognized as both
Calcitriol, metoprolol, flecainide, these two
frequency and duration entities), and (2) merge adjacent
named entities of the same semantic type: ‘q6h’ and ‘prn’ were
first recognized individually as frequency and then merged.
< Word and sentence segmentation was then performed.
Having this step after the NER module allows the
7-day course, 35 days, # for 7 days, 5 more
disambiguation of characters, such as punctuation, dashes,
slashes, etc, that are widely used within discharge summaries
Elevation of parathyroid hormone, rate control
often altering the segmentation process.
J Am Med Inform Assoc 2010;17:549e554. doi:10.1136/jamia.2010.004036
System architecture for the extraction of medication-related information and for establishing dependencies among the annotations. POS,
< Term and semantic tagging was used to detect drugs and
reasons. The system also performed the longest match and
Some medication names (eg, iron) are ambiguous: they can
merged adjacent medication terms: in ‘singulair (montelu-
correspond to biological characteristics or drugs. They were first
kast)’, the two drugs correspond to two separate entities in
assigned a specific semantic tag. Then, if they occurred in listings
or medication-related sections (box 3, example ii), their tags
< Term extraction was performed with YATEA40: it organizes
were modified into drug names. Otherwise, they were not
the identification of missing medication names and reasons
during the post-processing step. Part-of-speech tagging andlemmatization were performed with Genia.41
Detection of negative contexts and allergies
Our system deals with several contexts where medication names
In charge of several treatments on drugs and related information
do not correspond to prescriptions (box 3, examples iiiev). In
and computing dependency relations, the post-processing step
example iii, drug names are related to allergies: a specific module
exploits annotations from the processing step.
detects this relation and such drugs are not extracted. In
J Am Med Inform Assoc 2010;17:549e554. doi:10.1136/jamia.2010.004036
Box 2 Excerpts from four regular expressions for the
Box 3 Examples of textual data to be processed
extraction of mode (1, 2) and frequency (3,4) information
i. Heme. Anemia workup. Iron 49, TIBC 256, B12 555, folate
Pipe and parentheses allow disjunction of strings, while square
normal, ferritin 102, reticulocyte 7.9, and Epogen level 19.
brackets allow disjunction of characters, \n means end of lines
ii. HOME MEDS: methadone 20 bid, imdur 120 bid, hydral taking
and ? means an optional string or character, and back slash (\) is
25 bid, lasix 20 bid, coumadin, colace, iron, nexium 40 bid,
used to despecialize characters. Strings with the $ symbol indi-
cate variables: they are described in the second part of this
iii. ALLERGY: prednisone, penicillins, tamsulosin, simvastatin,
example. The first regular expression detects entities such as to
each nostril, under the tongue, by mouth; the second expression
iv. . did not require medications for abdominal pain
detects nasal, drip, inhaled, subq; the third expression detects
v. INR’s will be followed by Coumadin clinic; insulin-dependent
once a day, two per day, 2 per day; and the last expression
vi. . Methadone 20 bid, Ofloxacin 200 mg p.o. q 12, Insulin
1. ($adv)($sep)?($det|$adj)?($sep)?($anatomy)
2. (subcutaneously|subcutaneous|subcutane|subcu|subquta-
vii. . history of atrial flutter controlled on Amiodarone
neously|subqutaneous|subqtane|subq|inhaled|inh|iv|intra-
viii. . started on calcitriol given elevation of parathyroid
venously|intravenous|intraven|neb|drip|injection|inj|im|
intramuscularly|intramuscular|intramusc)s?
ix. . started on metoprolol 12.5 mg p.o. q.6 h. for rate control
3. ($number)($sep)?(a|per|$det)($sep)?d(ay)?
x. . should be switched to Toprol as her blood pressure
xi. She was initially diuresed with IV Lasix.
adv ¼ (through|per|by|with|via|in|to|under)
xii. packed red blood cells, red blood transfusions, red blood cell,
autologous red blood cells, blood, autologous blood, prbcs,
xiii. ., HCTZ 25 mg PO QD, Norvasc 10 mg PO QD, Pavachol
number ¼ ([0e9]+|once|one|two|twice|three|four)
as the majority are not relevant for the reason category.
example iv, drugs occur in negative context, detected with
Combining noun phrases with 52 contextual patterns (‘for’,
a NegEx-inspired algorithm: it exploits the proximity of pre- and
‘given’, ‘controlled on’, .) allows them to be constrained
post-negation markers. In example v, drug names appear in other
contexts: within names of diseases and institutions. This situ-ation is processed through an extension of NegEx resources:
proximity of terms such as ‘clinic’, ‘dependent’ or ‘deficiency’
Evaluation was performed by organizers of the challenge:
allows these drugs to be not detected as prescriptions.
automatically generated results are compared with the 251documents from ground truth according to the protocol
described by Uzuner et al.34 The main evaluation measure is the
With the rapid evolution of therapeutic research, new drugs
F-measure computed for exact and inexact matches.
appear,24 but drug nomenclatures cannot keep pace. We proposea novel method for a more exhaustive identification of newdrugs. The main indication we rely on is that drugs often occur
in specific semantic contexts together with medication-related
Table 2 presents results for our system in terms of F-measure F,
information (box 3, example vi). The corresponding semantic
precision P and recall R. The global exact-match F-measure was
pattern is: m do mo? f, where medication name, m (‘metha-
0.78. Within the challenge framework, our system ranked 7th
done’, ‘ofloxacin’, .), is followed by dosage, do (‘20’, ‘200 mg’,
out of 20 participating systems. The system generated good
‘12 units’), possibly followed by administration mode, mo (‘p.o.’,
results (F-measure over 0.81) for four categories (drug, dosage,
‘subcu’), and followed by frequency, f (‘twice daily’, ‘q 12’, ‘q p.
frequency, mode). The two remaining categories (duration and
m.’). If all entities (do, mo and f) except the first one are
reasons) were extracted with lower performance (F-measure 0.36
recognized, we infer that the first entity is a new drug name. We
and 0.29, respectively). Exact match performed slightly better
additionally check whether this entity is a stopword and
than inexact match. Within the interval of medication occur-
whether its ending is typical of drug endings (eg, ‘ine’, ‘one’,
rences,2 11 6 the mean number of medications per document was
‘ase’, ‘ate’, ‘cin’, ‘rin’).
35.6. Only one document has no mention of drugs.
Reasons are identified by two approaches: (1) the use of termi-
As shown in table 3, the performances obtained on the training
nological resources; (2) the use of noun phrase extraction
(n¼17) and test sets were comparable. Stability of the system
together with reason markers. The first approach applies only
was a positive result, especially given the very small set of
Snomed International terms and patient complaints. The second
annotated training data. We assume that the system may be
approach allows the sensitivity of this vocabulary to be
useful for the processing of other clinical records, or at least can
increased through extraction of noun phrases. However,
be easily adapted. Overall, it allows processing of narrative
exploiting all these noun phrases can be disastrous for precision,
clinical documents and extraction of several medication-related
J Am Med Inform Assoc 2010;17:549e554. doi:10.1136/jamia.2010.004036
Test set: performance of the system for exact and inexact
The most commonly recurring problem is associated with
reason detection: in examples xexi (box 3), our system wrongly
extracts ‘blood pressure’ as the reason for administration of
‘toprol’ and ‘diuresed’ as the reason for ‘IV Lasix’.
We found several cases of false negatives among drug names:
1. Ambiguous drug names (eg, ‘iron’, ‘statin’, ‘blood’, ‘magne-
sium’, ‘glucose’) corresponding to administered products but
not occurring in expected positive contexts
2. Terms such as ‘fluids’, ‘agents’ or ‘medication’ that we
3. Some classes of drugs (eg, ‘antianginal therapy’, ‘pressure
medications’) missing from our resources
4. New drug names (eg, ‘vp-16’, ‘ducolox’, ‘vasopressor’,
data with good performance, making the tedious manual
‘guqifenesin’) that did not occur within expected semantic
The core platform for NLP processing relies on standard NLP
5. Misspellings and abbreviations (eg, ‘aspirin325’, ‘hep.’)
steps (NER, tokenization, part-of-speech (POS) tagging,
6. Pronominal phrases (eg, ‘these medications’)
lemmatization), but also on specific modules designed for this
Blood products remain difficult to detect, as they seldom
appear within listings but mainly in narrative sections. More-
over, their nomenclature is not standardized, and various phrases
dallows disambiguation of several cases where punc-
tuation does not stand for sentence boundaries. Implementation
are used to refer to a blood transfusion (box 3, example xii). An
of the tools and modules used within the Ogmios platform also
extension of semantic patterns may be helpful: ‘required’ and
facilitates communication between them, making the manage-
‘one unit of’ are valuable indicators that ‘blood’ was adminis-
ment of linguistic and semantic annotations easier.39 In addi-
tered in the phrase ‘required one unit of blood during her
tion, the integration of modules with regular expressions is also
easy and does not conflict with other modules and tools.
An additional analysis was performed of the module for detec-
An analysis of these results was performed on 26 randomly
tion of new medication names. It extracted 49 occurrences, 15 of
selected discharge summaries from the ground truth (10%).
which are real drug names (precision¼30%), such as ‘pendalol’,
Within this set, a total of 729 medication annotations were
‘lithium’, ‘permatol’, ‘levoxine’ or ‘pavachol’ (box 3, example xiii).
analyzed: 380 were identical and 47 overlapped with the refer-
The precision is low, but it should be noted that we used it for
ence annotations. In the remaining annotations, at least one
enriching an already large drug nomenclature (over 240 000
category was different. This difference may correspond to false-
entries) and it missed only a few occurrences (such as ‘guqife-
positive (n¼70) or false-negative (n¼162) annotations.
nesin’). A more thorough evaluation of this module is ongoing.
We found only 16 (2%) false positives due to the extraction of
Other false negatives correspond to missed drug-related
wrong medication names, which attests to the quality of the
information. It is seldom due to the incompleteness of the
drug lexicon. However, a few entries (ie, ‘acute phase reactant’,
defined rules, but to wrong computation of dependency rela-
‘haemophilus influenzae’, ‘chewable’) remained that were
tions. Syntactic parsing42 43 may be helpful for this.
wrongly considered as drugs. The quality of medication lexica isa common problem19 31: with the original RxNorm, the
F-measure falls to 40.73%. Early in our experience, we observed
We have described a system developed for the annotation and
this fact and manually removed a large number of entries.
extraction of medication-related information from narrative
Nevertheless, additional filtering is required. It cannot be done
discharge summaries. We looked at this task as an annotation
using a vocabulary of common English words, as in Sirohi and
and annotation-disambiguation problem. Specific semantic
Peissig,19 because nearly all these entries are relevant to the
resources were exploited in a rule-based approach. We also
medical area: cleaning them up would instead require additional
proposed a novel module for detection of new medication names
manual work or contextual rules. Another category of noise
through the exploitation of semantic patterns. Global perfor-
among the extracted drugs is related to ambiguous medication
mances of our system (F-measure 0.78) rate it 7th among the 20
names that escaped our attention or for which the context is not
participants of the I2B2 challenge. Our system provides an F-
indicative of their semantics. False positives within medication-
measure of over 0.81 for extraction of medication names, their
related information are often due to wrong semantic relations.
frequency, dosage and mode of administration; however, itperforms poorly with duration and reasons, which is also thecase for other participating systems.
Training set: performance of the system for exact and inexact
Among the benefits are: improved duration extraction
through exploitation of prepositional phrases; improved reason
extraction with extended noun phrases; further evaluation of
the module for deducing new medications; improved establish-ment of dependency relations between drug names and the
Acknowledgments We are grateful to: the organizers of the I2B2 challenge for
preparing and providing such an exciting framework for the evaluation of text mining
systems; the anonymous reviewers for helpful and constructive comments; and
J Am Med Inform Assoc 2010;17:549e554. doi:10.1136/jamia.2010.004036
Provenance and peer review Not commissioned; externally peer reviewed.
Cimino JJ, Bright TJ, Li J. Medication reconciliation using natural languageprocessing and controlled terminologies. Stud Health Technol Inform 2007:679e83.
WHO. The use of stems in the selection of international nonproprietary names (inn) forpharmaceutical substances. Technical report. Geneva: World Health Organization, 2006.
Segura-Bedmar I, Martinez P, Segura-Bedmar M. Drug name recognition and
WHO. International drug monitoring: the role of national centers. Geneva,
classification in biomedical texts. Drug Safety 2008;13:816e23.
Switzerland: World Health Organization, 1972.
Xu R, Morgan A, Das AK, et al. Investigation of unsupervised pattern learning
FDA. Good pharmacovigilance practices and pharmacoepidemiologic assessement.
techniques for bootstrap construction of a medical treatment lexicon. Proceedings of
Rockville, MD: Food and Drug Administration, 2005.
Pronovost P, Weast B, Schwarz M, et al. Medication reconciliation: a practical tool
Gold S, Elhadad N, Zhu X, et al. Extracting structured medication event information
to reduce the risk of medication errors. J Crit Care 2003;18:201
from discharge summaries. AMIA Annu Symp Proc 2008:237
Bates D, Leape L, Cullen D, et al. Effect of computerized physician order entry and
Turchin A, Morin L, Semere L, et al. Comparative evaluation of accuracy of
a team intervention on prevention of serious medication errors. JAMA
extraction of medication information from narrative physician notes by commercial
and academic natural language processing software packages. AMIA Annu Symp
Teich J, Merchia P, Schmiz J, et al. Effects of computerized physician order entry on
prescribing practices. Arch Intern Med 2000;160:2741
Jagannathan V, Mullett C, Arbogast J, et al. Assessment of commercial nlp
Oren E, Shaffer E, Guglielmo B. Impact of emerging technologies on medication
engines for medication information extraction from dictated clinical notes. Int J Med
errors and adverse drug events. Am J Health Syst Pharm 2003;60:1447
Boussadi A, Bousquet C, Sabatier B, et al. Specification of business rules for the
Evans DA, Brownlow ND, Hersh WR, et al. Automating concept identification in the
development of hospital alarm system: application to the pharmaceutical validation.
electronic medical record: an experiment in extracting dosage information. Proc
Imming P, Sinning C, Meyer A. Drugs, their targets and the nature and number of
Iglesias JE, Rocks K, Jahanshad N, et al. Tracking medication information across
drug targets. Nat Rev Drug Discov 2006;5:821
medical records. Proc AMIA Annu Fall Symp 2009:266
Rader D, Daugherty A. Translating molecular discoveries into new therapies for
Xu H, Stenner S, Doan S, et al. MedEx: a medication information extraction system
for clinical narratives. J Am Med Inform Assoc 2010;17:19
Hale R. Text mining: getting more value from literature resources. Drug Discov Today
Shah AD, Martinez C. An algorithm to derive a numerical daily dose from
unstructured text dosage instructions. Pharmacoepidemiol Drug Saf 2006;15:161
McDonald C, Tierney W. The medical gopher
Hripcsak G, Friedman C, Alderson P, et al. Unlocking clinical data from narrative
find, organize and decide about patient data. West J Med 1986;145:823
reports: a study of natural language processing. Ann Intern Med 1995;122:681
Poon E, Blumenfeld B, Hamann C, et al. Design and implementation of an application
¨, Solti I, Cadag E. Extracting medication information from clinical text.
and associated services to support interdisciplinary medication reconciliation efforts
J Am Med Inform Assoc 2010;17:514e8.
at an integrated healthcare delivery network. J Am Med Inform Assoc
Simon L, Wei M, Robin M, et al. Rxnorm: prescription for electronic drug information
Manley H, Drayer D, McClaran M, et al. Drug record discrepancies in an outpatient
RxNorm, a standardized nomenclature for clinical drugs. Technical report, National
electronic medical record: frequency, type, and potential impact on patient care at
Library of Medicine. Bethesda, Maryland, 2009. http://www.nlm.nih.gov/research/
a hemodialysis center. Pharmacotherapy 2003;23:231
Grant R, Devita N, Singer D, et al. Improving adherence and reducing medication
´ RA, Rothwell DJ, Palotay JL. SNOMED InternationaledThe systematized
discrepancies in patients with diabetes. Ann Pharmacother 2003;37:962
nomenclature of human and veterinary medicine. College of American Pathologists –
Thomsen L, Winterstein A, Søndergaard B, et al. Systematic review of the incidence
American Veterinary Medical Association, Northfield, 1993.
and characteristics of preventable adverse drug events in ambulatory care. Ann
ˆte´ RA. The SNOMED model: a knowledge source for the
controlled terminology of the computerized patient record. Methods Inf Med
Rindflesch T, Tanabe L, Weinstein J, et al. EDGAR: extraction of drugs, genes and
relations from the biomedical literature. Pac Symp Biocomput 2008:517
Hamon T, Nazarenko A, Poibeau T, et al. A robust linguistic platform for efficient and
´rik C, Hofmann-Apitius M, Zimmermann M, et al. Identification of new drug
domain specific web content analysis. In Proceedings of RIAO 2007 (electronic
classification terms in textual resources. Bioinformatics 2007;23:264
Chen E, Hripcsak G, Xu H, et al. Automated acquisition of disease drug knowledge
Aubin S, Hamon T. Improving term extraction with terminological resources. In:
from biomedical and clinical documents: an initial study. J Am Med Inform Assoc
Salakoski T, Ginter F, Pyysalo S, et al, eds. Advances in natural language processing
(5th International Conference on NLP, FinTAL 2006), number 4139 in LNAI. Springer,
Sirohi E, Peissig P. Stufy of effect of drug lexicons on medication extraction from
electronic medical records. Pac Symp Biocomput 2005:308
Tsuruoka Y, Tateishi Y, Kim JD, et al. Developing a robust part-of-speech tagger for
Levin M, Krol M, Doshi A, et al. Extraction and mapping of drug names from free
biomedical text. LNCS 2005;3746:382e92.
text to a standardized nomenclature. AMIA Annu Symp Proc 2007:438
Charniak E. Immediate-head parsing for language models. In: Proceedings of the
Chhieng D, Day T, Gordon G, et al. Use of natural language programming to extract
39th Annual Meeting of the Association for Computational Linguistics. 2001:124e31.
medication from unstructured electronic medical records. AMIA Annu Symp Proc
Klein D, Manning CD. Accurate unlexicalized parsing. In: Proceedings of the 41st
Meeting of the Association for Computational Linguistics, 2003:423
J Am Med Inform Assoc 2010;17:549e554. doi:10.1136/jamia.2010.004036
What’s New in EIPS April 29, 2004 For Immediate Release Elk Island Public Schools (EIPS) is pleased to report on a number of exciting things that are happening for studentsand learning in schools throughout the division. Andrew School Celebrates Education Week Sponsored and supervised by the School Council, Andrew School will host a Learning Fair as an evening of displays and demonstrati
 Linguistic approach for identification of
Linguistic approach for identification of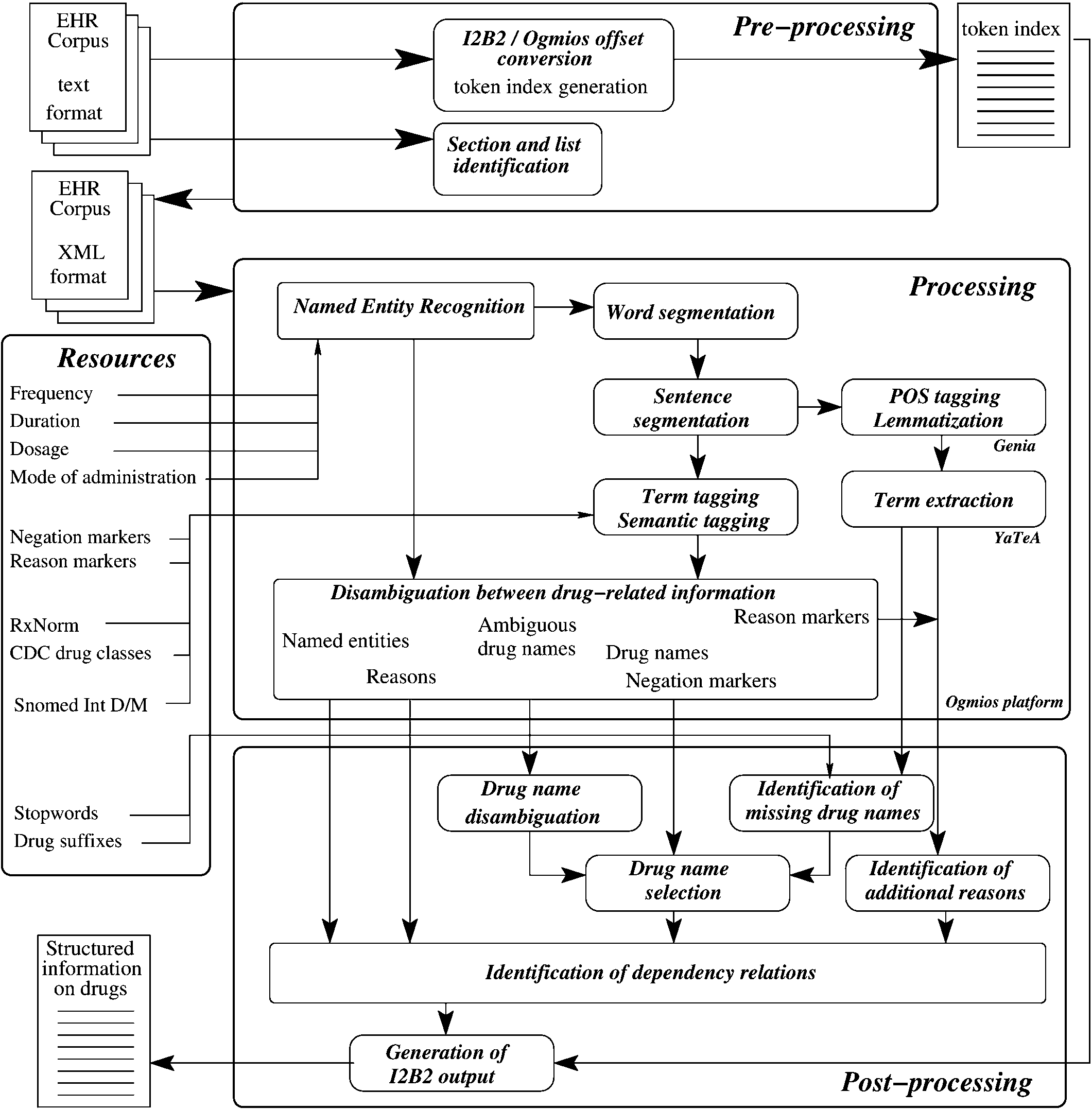 System architecture for the extraction of medication-related information and for establishing dependencies among the annotations. POS,
< Term and semantic tagging was used to detect drugs and
reasons. The system also performed the longest match and
Some medication names (eg, iron) are ambiguous: they can
merged adjacent medication terms: in ‘singulair (montelu-
correspond to biological characteristics or drugs. They were first
kast)’, the two drugs correspond to two separate entities in
assigned a specific semantic tag. Then, if they occurred in listings
or medication-related sections (box 3, example ii), their tags
< Term extraction was performed with YATEA40: it organizes
were modified into drug names. Otherwise, they were not
the identification of missing medication names and reasons
during the post-processing step. Part-of-speech tagging andlemmatization were performed with Genia.41
Detection of negative contexts and allergies
Our system deals with several contexts where medication names
In charge of several treatments on drugs and related information
do not correspond to prescriptions (box 3, examples iiiev). In
and computing dependency relations, the post-processing step
example iii, drug names are related to allergies: a specific module
exploits annotations from the processing step.
System architecture for the extraction of medication-related information and for establishing dependencies among the annotations. POS,
< Term and semantic tagging was used to detect drugs and
reasons. The system also performed the longest match and
Some medication names (eg, iron) are ambiguous: they can
merged adjacent medication terms: in ‘singulair (montelu-
correspond to biological characteristics or drugs. They were first
kast)’, the two drugs correspond to two separate entities in
assigned a specific semantic tag. Then, if they occurred in listings
or medication-related sections (box 3, example ii), their tags
< Term extraction was performed with YATEA40: it organizes
were modified into drug names. Otherwise, they were not
the identification of missing medication names and reasons
during the post-processing step. Part-of-speech tagging andlemmatization were performed with Genia.41
Detection of negative contexts and allergies
Our system deals with several contexts where medication names
In charge of several treatments on drugs and related information
do not correspond to prescriptions (box 3, examples iiiev). In
and computing dependency relations, the post-processing step
example iii, drug names are related to allergies: a specific module
exploits annotations from the processing step.