Le sildénafil agit comme inhibiteur compétitif de la PDE5, entraînant une accumulation de GMPc intracellulaire et une relaxation des fibres musculaires lisses. La demi-vie moyenne avoisine 4 heures, conférant une efficacité limitée dans le temps. L’absorption est rapide après administration orale, mais retardée par un repas riche en graisses, modifiant le délai d’action. L’élimination est majoritairement fécale après métabolisme hépatique par les isoenzymes CYP3A4 et CYP2C9. Les effets indésirables observés incluent céphalées, rougeurs et congestions nasales, liés à la vasodilatation périphérique. Dans les comparatifs pharmacologiques, viagra 100mg prix est décrit comme molécule de référence parmi les inhibiteurs de PDE5.
Microsoft word - model paper.doc
From GLM to GLIMMIX-Which Model to Choose?
Patricia B. Cerrito, University of Louisville, Louisville, KY
ABSTRACT The purpose of this paper is to investigate several SAS procedures that are used in linear predictive models in SAS/Stat. The primary focus will be on the correct choice of model given the designated outcome variable, and the combination of input variables. Procedures to be discussed include GLM, LOGISTIC, GENMOD, MIXED, and GLIMMIX. PROC GLIMMIX is a relatively new SAS procedure, although it has been available as a macro for some time. There are three main types of variables used in linear models: nominal, ordinal, and interval. Nominal is defined as categorical (such as gender); ordinal is defined as categorical that can be ordered from least to most (such as employee evaluation rank); interval data can define ratios. While all of the models discussed can include all three types of input variables, the model choice is different if the outcome variable is interval or nominal. Another consideration for model choice is whether the input variables are fixed effects or random effects. Fixed effects are definitive, and will not change regardless of the sample data collection. Random effects can change when the experiment is replicated. Examples of random effects include subjects in a drug study, choice of items to compare between retail stores for market basket price differences, and classrooms in an education study. Examples will be discussed. INTRODUCTION An inappropriate model will provide inappropriate results. For those users of SAS who know SAS/Stat and PROC GLM, there are other models that are more appropriate to the collected data. It is necessary to fit the model to the data-not the data to the model (to a man with a hammer….) If regression is not appropriate because the assumptions are violated, change the model. There are several models readily available in SAS/Stat (Figure 1). Figure 1. Linear Models Available in SAS/Stat
Generalized Linear Mixed Model PROC GLIMMIX
Each model serves a different purpose, and should be used with different types of data. The purpose of this paper is to focus on model choice; it is not intended to provide all details concerning the use of each model. Should the investigator choose one of the models, details are available in on-line docs. Items that must be considered in model choice are
1. Type of outcome variable-whether nominal, ordinal, or interval 2. Type of input variable-whether nominal ordinal, or interval
3. Type of input variable-whether fixed or random effect 4. Choice of covariance matrix format for random effects 5. Choice of link function for non-normal residuals
As the complexity of the data increases, so, too, does the complexity of the model. Choices must be made, choices that impact model outcomes. Consider Table 1, which gives some indication as to how the models should be used. Table 1. Outline of Model Choice Model LOGISTIC Binary
Categorical, Interval, Fixed Effects only Log-Normal
Categorical, Interval, Fixed Effects only Normality
This paper will discuss the different models, and how to define outcomes and inputs, along with a consideration of the assumptions as listed in Table 1. PROC ANOVA and PROC REG
ANOVA should only be used for a balanced design in which every categorical choice is divided equally. If there are three treatments, then each treatment should have exactly the same number of observations. This procedure requires less computing time compared to PROC GLM. However, since a completely balanced design almost never happens with large samples, there is really no need to use ANOVA instead of GLM. PROC REG can only use interval or ordinal variables as inputs. In order to include nominal data, dummy variables need to be created. Too many nominal inputs requires considerable programming effort. Essentially, for each level of a nominal variable, PROC REG creates a new regression line that is parallel to the regression lines for all other levels of the same variable. While PROC REG has diagnostics that are of value, the same diagnostics have now been incorporated into PROC GLM. For this reason, it is better to use PROC GLM for all standard analyses. PROC GLM
In the past, PROC GLM was the most sophisticated procedure for performing a linear models analysis. It can use both interval and categorical variables as inputs; it now contains all of the diagnostic elements provided by PROC REG, and it does not require a balanced design. In addition, PROC GLM uses the Type III Sum of Squares to examine multiple types of treatments simultaneously. The one problem with PROC GLM is that is was never intended to be used with random effects. Special cases of random effects, such as nested designs and split plot designs have been developed for use with PROC GLM. Repeated measures, also, can be examined using PROC GLM provided that there are few subjects dropping out in the later time measurements. However, PROC GLM has become the model of choice that is used, and very little consideration is usually given to whether the inputs are fixed or random effects. Repeated measures represent a random effect since the choice of time points to collect measurements is somewhat arbitrary on the part of the investigator. Inputs such as age that are divided into blocks are also random effects since the blocks are arbitrary. For the same reason, Likert scales are random effects since it is somewhat arbitrary whether a 4-point or a 5-point scale is used. However, in many cases, these inputs are entered into PROC GLM as if they were fixed effects. However, as is true in the special cases of split plots and nested effects, assuming the effects are fixed when they are random will increase the size of the random error. That will decrease the overall size of the F-statistics. As a result, the model will have non-significant F-statistics that should be significant. Consider the following question, Should ordinal variables be defined as quantitative, or as classification variables in PROC GLM? Since ANOVA assumes class levels (ie nominal data), and regression assumes interval data, there is no real provision for ordinal variables. If defined as a class variable, many degrees of freedom will be used, but post- hoc tests can be made. If defined as interval, only one degree of freedom is used in the model but post-hoc tests are unavailable. Depending on the choice, model results can differ. Sample GLM code is listed below: PROCGLM DATA=WORK.SORT7659 ;
MODEL hours= CourseLevel expectknownever
SINGULAR=1E-07 ;
LSMEANS CourseLevel expectknownever / PDIFF=ALL ;
PROC LOGISTIC
PROC LOGISTIC is very similar to PROC GLM, although it has a binary outcome variable rather than an interval outcome. If the outcome is ordinal, PROC LOGISTIC can also be used, but with a complementary log-log link function instead of the more standard log function. Both PROC LOGISTIC and PROC GLM can place ordinal inputs either as class or as quantitative variables. Again, consideration of the degrees of freedom and the necessity of post-hoc tests should be made before deciding where to place the ordinal inputs. Frequently, logistic regression is used to divide a population into high risk/low risk. However, this dichotomous outcome is contrived. There could just as easily be 5 or 10 categories of risk. It is not necessary to reduce the number of outcomes to 2 just to fit the results into a logistic model. Logistic regression also defines odds ratios for the input variables. However, the default does not provide confidence limits for them. Therefore, the user should always use the option to print confidence limits. In addition, the user should examine the c-statistics. It is comparable to the r2 for the general linear model. If the outcome variable only has two levels, logistic regression can also print a classification table and a receiver operating curve. They can be used to define a cut-point to divide the population into the high/low categories. Standard code is given below: PROCLOGISTIC DATA=WORK.SORT7975 ;
SELECTION=NONE LINK=PROBIT CLPARM=WALD CLODDS=WALD ALPHA=0.05 ; OUTPUT
OUT=SASUSER.PRED3492(LABEL="Logistic
regression predictions and statistics for
SASUSER.QURY0181") PREDPROBS=INDIVIDUAL;
For ordinal (or nominal outcomes with more than 2 levels), the code used is
PROCLOGISTIC DATA=WORK.SORT1118 ;
SELECTION=NONE LINK=CLOGLOG CLPARM=WALD CLODDS=WALD ALPHA=0.05 ; OUTPUT
OUT=SASUSER.PRED1881(LABEL="Logistic
regression predictions and statistics for
SASUSER.QURY0181") PREDPROBS=INDIVIDUAL;
There are some cautions in order concerning logistic regression. Logistic regression will ALWAYS inflate results, especially if the group sizes are very different and one of the groups represents a rare event, For example, if one group size is 95% and one is 5%, then one classification rule (put all subjects in class A) will be 95% accurate.
Poisson regression should be used for rare events instead. If possible, fresh data should be used to examine the inflation rate of results. PROC MIXED
PROC MIXED has two components, y=αX+γZ+ε. If γ=0, then the mixed model is identical to the general linear model. If γ≠0, then there is some randomness in the model and some covariance between inputs. Special cases of the mixed model are repeated measures, nested designs, and split plot designs. Before the introduction of PROC MIXED, these three special cases were considered using PROC GLM, but with some changes to the error terms. PROC MIXED is a superior method for these cases. In order to use PROC MIXED, the covariance must be estimated in some way. If the investigator has no knowledge of how the input random effects correlate, the default unstructured matrix is the optimal choice. PROC MIXED has a number of possible covariance matrix designs that can be used-but only if the user has a good idea of the structure of the matrix. Standard code is PROCMIXED DATA = WORK.SORT5396 METHOD=REML ;
MODEL hours_modified= Applied CourseLevel Statistics
DDFM=CONTAIN OUTPM=WORK._PRE6476(LABEL="Predicted
; RANDOM CourseLevel / G TYPE=VC; LSMEANS Applied CourseLevel Statistics / PDIFF=ALL ;
PROC GENMOD
PROC GENMOD generalizes PROC LOGISTIC by allowing for more than binary outcomes. For the general linear model (GLM), the model equation takes the form Y=α+βX+ε so that the estimate is yˆ = β
is assumed normally distributed with mean zero and constant variance. For the generalized linear model, the
estimate changes to g( yˆ) = Xβ where g is called a link function. If g( yˆ) =
binary, then the model is the special case of logistic regression and PROC LOGISTIC can be used. If the outcome variable consists of count data then the link function g( ˆy) = log( ˆy) can be used. The assumption here is that the residuals have a Poisson distribution. However, this same link function can be used under the assumption that the residuals are interval data. In this case, the residuals are assumed to form a gamma distribution, which also includes the special case of the exponential distribution. There are a number of other distributions that can be used as well. The problem is that the residual distribution of
g( yˆ) = Xβ depends upon the model, and that model depends upon the choice of the link function. Possible link
functions are given in Table 2. Table 2. Examples of Link Functions in PROC GENMOD
occurrence) Continuous Normal
If the investigator has some domain knowledge that allows him to choose a link function, that function should be used. However, if the investigator cannot estimate the function, another way is to estimate Y=α+βX first using PROC GLM while saving the residuals in a dataset. The data can be used in PROC KDE to estimate the form of the distribution. The investigator can then choose the link function that comes closest to the kernel distribution. The kernel can be examined using the following code listed below. Figure 2 gives an example kernel density estimator.
prockde data=sasuser.qury0181; univar hours/gridl=0 gridu=25 out=sasuser.kdehours; run; PROCGPLOT DATA = sasuser.kdehours; PLOT density * value /
Figure 2. Results of PROC KDE
Standard code for PROC GENMOD is given below:
MODEL hours= Applied Statistics workhabits
LINK=LOG DIST=GAMMA TYPE3 CORRB LRCI CL ALPHA=0.05;
LSMEANS Applied Statistics workhabits / ALPHA=0.05;
PREDICTED=_predicted1 RESDEV=_resdev1 RESCHI=_reschi1; RUN; QUIT;
PROC GLIMMIX
This procedure generalizes the GENMOD procedure to include error terms that are not normally distributed. It also generalizes the MIXED procedure to allow for random effects in the model. However, the random effects must be
normal. The general format for GLIMMIX is
Class block a b; Model y=a b a*b / ddf=#; Random block a*block; Lsmeans a b a*b / diff;
Unlike PROC MIXED, PROC GLIMMIX does not have a repeated statement, and repeated measures are in the RANDOM statement. Possible link functions are given in Table 3. Table 3. Link Functions for PROC GLIMMIX Outcome Binomial Exponential Gaussian Geometric Lognormal Multinomial Negbinomial Tcentral Sample code is given below:
MODEL hours_modified= Applied CourseLevel Statistics
DDFM=CONTAIN dist=gamma ; RANDOM CourseLevel / G TYPE=VC; LSMEANS Applied CourseLevel Statistics / PDIFF=ALL ; RUN; QUIT;
EXAMPLES
Consider the following examples:
• A test to compare the effectiveness of CT scans to x-ray in the detection of lung cancer. Each patient is
randomized to receive x-ray only or CT only. 10,000 patients are in the sample, limited to high-risk patients. The outcome variable is the occurrence of lung cancer.
• A randomized clinical trial to compare treatment of osteomyelitis (MRSA) with vancomycin and Zyvox.
Patients are treated according to protocol, with follow up at 1, 2, 6, 12 months after end of treatment. What if the study is observational rather than randomized?
In the first example, the occurrence of lung cancer is rare. Therefore, a Poisson distribution would better fit the study than a logistic regression. In the second, the measure of recurrence is a repeated measure. While it can also be
examined using survival analysis, the fact that measurements are at fixed intervals rather than continuous will also allow for a mixed models design.
CONCLUSION
While it is possible to use PROC GLIMMIX as the most complex of the models, it is not advisable. Even so, choices as to random versus fixed effects, link function, and covariance matrix still have to be made. Therefore, the investigator should use the simplest procedure that will accommodate the variable choices.
Patricia Cerrito University of Louisville Department of Mathematics Louisville, KY 40292 502-852-6826 502-852-7132 (fax) [email protected]
SAS and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc. in the USA and other countries. ® indicates USA registration. Other brand and product names are trademarks of their respective companies.
Akamatsu, Carol Tane. The acquisition of fingerspelling in preschool children. Doctoraldissertation, University of Rochester, 1982. Anderson, John R. (Ed.). Cognitive Skills and Their Acquisition. Hillsdale, N.J.: Erlbaum, 1981. Barber, E. J. W. Archaeological Decipherment. Princeton: Princeton University Press, 1974. Barber, E. J. W. Language acquisition and applied linguistics. ADFL Bulle
Malaria Control—A Glimmer of Hope The quotation that follows is from The Lake Regions of Central Africa by Sir Richard Burton (1821-1890). Sir Burton was an adventurer whose visits to the Far East and Africa brought him into contact with the greatest killer of humanity, Plasmodium falciparum . The approach of malignant fever is very insidious. An attack begins mostly with an ordinar
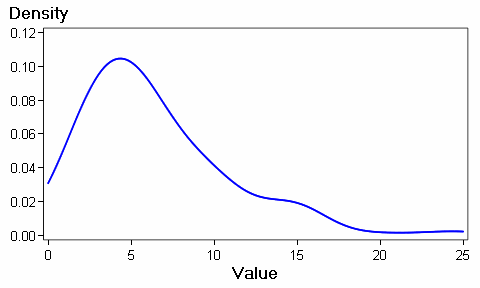 If the investigator has some domain knowledge that allows him to choose a link function, that function should be used. However, if the investigator cannot estimate the function, another way is to estimate Y=α+βX first using PROC GLM while saving the residuals in a dataset. The data can be used in PROC KDE to estimate the form of the distribution. The investigator can then choose the link function that comes closest to the kernel distribution. The kernel can be examined using the following code listed below. Figure 2 gives an example kernel density estimator.
proc kde data=sasuser.qury0181;
If the investigator has some domain knowledge that allows him to choose a link function, that function should be used. However, if the investigator cannot estimate the function, another way is to estimate Y=α+βX first using PROC GLM while saving the residuals in a dataset. The data can be used in PROC KDE to estimate the form of the distribution. The investigator can then choose the link function that comes closest to the kernel distribution. The kernel can be examined using the following code listed below. Figure 2 gives an example kernel density estimator.
proc kde data=sasuser.qury0181;